service@sumr.org
021 - 6160 - 6918
Uber数据模型,准确预料你的行踪
2014-09-24

所有人都知道,Uber素来特别重视数据资料,它的共乘服务就是基于数据分析之上,并欢迎乘客和司机彼此互评。不过,Uber的数据学家不仅仅是研究服务的核心的功能,还经常钻研一些乘客细节,并常获得意外的收获。
根据贝氏机率, Uber的数据小组可以根据75%的机率,准确地预测乘客的目的地。他们还有一套专门的算法,用以寻找出特定目的地,而且是准确的地址。随后,他们在3,000名Uber乘客做了测试。
Uber的Ren Lu最近公开了他们的公式运作方式 :
他们选取了3000名不同的乘客,于2014年前在旧金山的搭乘路线。每趟不具名的旅程里,乘客都以向Uber 叫车时填写的目的地进行了标注。他们假设这代表着乘客们的真正目的地,为此还创造一个‘黄金标准’,来跟他们的模型的预测结果进行比较。
Uber的公式里有三项变数,包括用户的历史纪录、其他用户的行为,与特地区域的总人口。
公式在数学上,将这些“先验机率”进行融合,再结合别的因素去判断一个用户目的地是酒吧或咖啡厅。在纽约或旧金山这种人口高密度的都市来说很难,也是无法用传统反向地理解析的坐标或公开位置数据库做得到的。
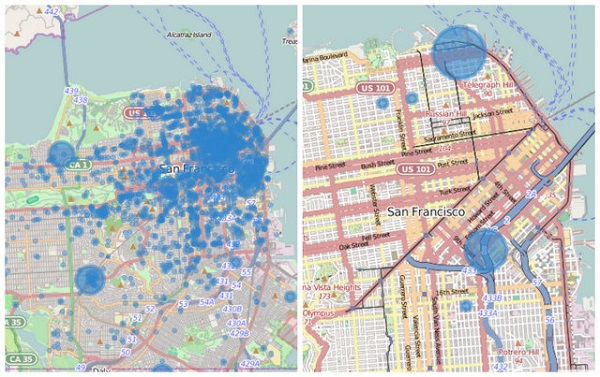
一个人过去做了何事?经常造访的是哪个特定酒吧? Uber 的用户都去何处?这类人口多数是做什么的?这是此类算法必须问的基本问题。
最终,它将智能地计算别的因素,比如一天中的时段、距离、甚至是目的地的邮政编码。
为何这很重要?跟别的现代化公司相同, Uber想深入了解客户,还有很长的路要走。 Lu说:我们的搭乘模型是Uber 数据小组试图改善搭乘经验而做的努力。该计划具有建构更复杂的先验机率与可能性。
也就是说, Uber预测的真正目的并非是乘客的最终目的地。有了此刻实验和模型, Uber的预测能力将日益增强,乘客的搭乘经验自然会跟着提升。